Introduction
AI doesn’t have to be opaque, mysterious, over‑engineered, or powered by massive deep‑learning models to be effective. Some of the most useful systems are built by thoughtfully combining classical machine‑learning techniques with explicit, human‑readable rules. This edition implements a Python program called “Budget Categorizer & Spending Insights AI” as a strong and tangible example of this approach in action. The application takes everyday financial transactions and transforms them into clear, actionable insights, thus demonstrating how hybrid AI systems can support real decision‑making while remaining interpretable and maintainable.
The Problem: Data Without Insight
Most people generate dozens—sometimes hundreds—of financial transactions each month. Individually, these transactions are easy to understand. Collectively, they become noise. Patterns are hard to see, anomalies go unnoticed, and spending habits remain opaque.
The goal of this project was simple but meaningful:
turn raw transaction data into understandable categories, highlight unusual behavior, and provide concrete guidance a human can act on.
A Hybrid AI Approach That Works
Instead of relying on deep learning, the system deliberately uses a hybrid AI architecture, blending machine learning with expert‑system logic:
Machine Learning
- TF‑IDF converts merchant names and transaction descriptions into numerical features.
- Logistic Regression predicts spending categories (e.g., Groceries, Dining, Utilities).
- KMeans clustering uncovers latent spending patterns that can inform future enhancements.
Expert System Logic
- Explicit merchant‑to‑category rules encode domain knowledge (e.g., “Starbucks” → Dining).
- Threshold‑based rules flag anomalies, such as unusually high dining expenses.
- The system generates human‑readable explanations, showing whether a decision came from a rule, a model, or both.
When both rules and model predictions are available, the system prioritizes symbolic knowledge—ensuring predictable and explainable outcomes.
Why the Architecture Matters?
The real strength of this project isn’t any single algorithm—it’s how the pieces are orchestrated. The application follows a clear, goal‑driven execution flow:
Load data → build features → cluster → classify → apply rules → generate insights → report
This mirrors concepts from symbolic planning, where each step transforms the system’s knowledge state and contributes to a coherent end goal. The result is an AI pipeline that is easy to reason about, debug, and extend.
Interpretability as a First-Class Feature
A key design choice was to favor interpretability over complexity.
For small, structured text data like merchant names and transaction descriptions, classical machine‑learning methods are:
- Sufficiently accurate
- Easier to explain
- Less costly to maintain
By avoiding unnecessary deep learning, the system remains transparent. Users don’t just see what was flagged—they see why. This is critical for trust, especially in decision‑support systems.
Why This Matters for Interop?
From an interoperability and platform‑engineering perspective, this project reinforces an important lesson:
Effective AI is about choosing the right techniques—not the most fashionable ones.
By combining symbolic reasoning with statistical learning, the system achieves:
- Clear boundaries between logic and learned behavior
- Explainable outcomes suitable for enterprise contexts
- A modular design that can evolve without re‑architecting everything
This is a pattern worth repeating across internal tools, platforms, and AI‑enabled services.
Code Listing
# File: main.py
# Written by: Angel Hernandez
# This project is a budget categorizer & Spending insights AI application
import os
import sys
import subprocess
import textwrap
class DependencyChecker:
@staticmethod
def ensure_package(package_name):
try:
__import__(package_name)
except ImportError:
print(f"Installing missing package: {package_name}...")
subprocess.check_call([sys.executable, "-m", "pip", "install", package_name])
print(f"Package '{package_name}' was installed successfully.")
class SyntheticDataFactory:
@staticmethod
def get_data():
return [
("2026-02-01", "Safeway", "Groceries and household items", 85.23, "Groceries"),
("2026-02-02", "Starbucks", "Coffee and snack", 7.50, "Dining"),
("2026-02-03", "Shell", "Gas station fuel", 52.10, "Transportation"),
("2026-02-04", "Netflix", "Monthly subscription", 15.99, "Entertainment"),
("2026-02-05", "Amazon", "Electronics purchase", 220.00, "Shopping"),
("2026-02-06", "PUD", "Electric utility bill", 130.45, "Utilities"),
("2026-02-07", "Safeway", "Groceries", 95.10, "Groceries"),
("2026-02-08", "Chipotle", "Lunch burrito", 13.25, "Dining"),
("2026-02-09", "Lyft", "Ride to airport", 48.75, "Transportation"),
("2026-02-10", "Disney+", "Streaming subscription", 9.99, "Entertainment"),
("2026-02-11", "Home Depot", "Home improvement supplies", 180.00, "Shopping"),
("2026-02-12", "City Water", "Water utility bill", 60.30, "Utilities"),
("2026-02-13", "Safeway", "Groceries and snacks", 72.40, "Groceries"),
("2026-02-14", "Local Bistro", "Dinner with family", 120.00, "Dining"),
("2026-02-15", "Shell", "Snacks and Drinks", 40.00, "Transportation"),
("2026-02-16", "Spotify", "Music subscription", 10.99, "Entertainment"),
("2026-02-17", "Target", "Clothing and toys", 150.00, "Shopping"),
("2026-02-18", "Gas & Power Co", "Gas utility bill", 90.00, "Utilities"),
("2026-02-19", "Fancy Steakhouse", "Anniversary dinner", 550.00, "Dining"),
("2026-02-20", "Seafood Restaurant", "Celebration dinner", 620.00, "Dining")
]
class RuleEngine:
def __init__(self):
self.__dining_anomaly_threshold = 500.0
self.__merchant_category_map = {
"safeway": "Groceries",
"whole foods": "Groceries",
"starbucks": "Dining",
"chipotle": "Dining",
"shell": "Transportation",
"lyft": "Transportation",
"uber": "Transportation",
"netflix": "Entertainment",
"disney+": "Entertainment",
"spotify": "Entertainment",
"pud": "Utilities",
"city water": "Utilities",
"gas & power co": "Utilities",
"home depot": "Shopping",
"target": "Shopping",
"amazon": "Shopping",
}
def __infer_category_from_merchant(self, merchant: str):
m = merchant.strip().lower()
for key, cat in self.__merchant_category_map.items():
if key in m:
return cat
return None
def apply_rules(self, row, model_category: str | None):
merchant = str(row.get("merchant", ""))
amount = float(row.get("amount", 0.0))
explanation_parts = []
rule_cat = self.__infer_category_from_merchant(merchant)
if rule_cat:
explanation_parts.append(f"Rule: Merchant '{merchant}' implies category '{rule_cat}'.")
anomaly_flag = False
candidate_cat = rule_cat or model_category or "Uncategorized"
if candidate_cat == "Dining" and amount > self.__dining_anomaly_threshold:
anomaly_flag = True
explanation_parts.append(f"Rule: Amount {amount:.2f} > {self.__dining_anomaly_threshold:.2f} → Flag as unusual.")
final_cat = rule_cat or model_category or "Uncategorized"
if model_category and not rule_cat:
explanation_parts.append(f"Model: Logistic Regression predicted '{model_category}'.")
explanation = " ".join(explanation_parts) if explanation_parts else "No rules fired."
return {
"rule_category": rule_cat,
"final_category": final_cat,
"is_anomaly": anomaly_flag,
"explanation": explanation,
}
class BudgetCategorizer:
def __init__(self):
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans as kmeans
from sklearn.feature_extraction.text import TfidfVectorizer as tfidvectorizer
from sklearn.preprocessing import LabelEncoder as labelencoder
from sklearn.linear_model import LogisticRegression as logisticregression
self.__np = np
self.__pd = pd
self.__kmeans = kmeans
self.__label_encoder = labelencoder
self.__tfidvectorizer = tfidvectorizer
self.__logistic_regression = logisticregression
def __load_transactions(self, path: str | None = None):
if path is not None and os.path.exists(path):
retval = self.__pd.read_csv(path)
retval.columns = [c.strip().lower() for c in retval.columns]
else:
retval = self.__pd.DataFrame(SyntheticDataFactory.get_data(),
columns=["date", "merchant", "description",
"amount", "category"])
retval.columns = [c.strip().lower() for c in retval.columns]
retval["merchant"] = retval["merchant"].fillna("")
retval["description"] = retval["description"].fillna("")
retval["amount"] = retval["amount"].fillna(0.0).astype(float)
if "category" not in retval.columns:
retval["category"] = self.__np.nan
return retval
def __build_text_features(self, df):
texts = (df["merchant"].astype(str) + " " + df["description"].astype(str)).tolist()
vectorizer = self.__tfidvectorizer(stop_words="english", max_features=500)
x_text = vectorizer.fit_transform(texts)
return vectorizer, x_text
def __perform_clustering(self, x_text, n_clusters: int = 4):
kmeans = self.__kmeans(n_clusters=n_clusters, random_state=42, n_init=10)
cluster_labels = kmeans.fit_predict(x_text)
return kmeans, cluster_labels
def __train_classifier(self, df, x_text):
labeled_mask = df["category"].notna()
mask = labeled_mask.to_numpy()
x_labeled = x_text[mask]
y_labeled = df.loc[mask, "category"].astype(str)
label_encoder = self.__label_encoder()
y_encoded = label_encoder.fit_transform(y_labeled)
clf = self.__logistic_regression(max_iter=300, class_weight="balanced")
clf.fit(x_labeled, y_encoded)
return clf, label_encoder
@staticmethod
def __predict_categories(df, vectorizer, clf, label_encoder):
texts = (df["merchant"].astype(str) + " " + df["description"].astype(str)).tolist()
x_text = vectorizer.transform(texts)
y_pred = clf.predict(x_text)
return label_encoder.inverse_transform(y_pred)
@staticmethod
def __heuristic_select_category(rule_cat, model_cat):
return rule_cat or model_cat or "Uncategorized"
@staticmethod
def __generate_insights(df):
retval = {}
recommendations = []
cat_totals = df.groupby("final_category")["amount"].sum().sort_values(ascending=False)
retval["category_totals"] = cat_totals
anomalies = df[df["is_anomaly"] == True]
retval["anomalies"] = anomalies
total_spend = df["amount"].sum()
for cat, total in cat_totals.items():
share = total / total_spend if total_spend > 0 else 0.0
if share > 0.30 and cat not in ["Utilities"]:
plan_steps = [f"Review recurring subscriptions or habits in '{cat}'.",
f"Set a monthly budget cap for '{cat}' at {0.8 * total:.2f}.",
f"Track '{cat}' transactions weekly and pause non-essential purchases."]
recommendations.append({"category": cat, "share": share, "plan_steps": plan_steps})
retval["recommendations"] = recommendations
return retval
@staticmethod
def __print_report(df, insights,records_to_show):
wrapper = textwrap.TextWrapper(width=80)
print("\n================ Budget Categorizer & Spending Insights Report ================\n")
print("Sample of categorized transactions:")
df["amount"] = df["amount"].apply(lambda x: f"${x:,.2f}")
print(df[["date", "merchant", "description", "amount", "final_category", "is_anomaly"]].head(records_to_show))
print()
print("Category totals:")
for cat, total in insights["category_totals"].items():
print(f" - {cat}: ${total:.2f}")
print()
if len(insights["anomalies"]) > 0:
print("Unusual expenses flagged:")
for _, row in insights["anomalies"].iterrows():
print(
f" - {row['date']} | {row['merchant']} | {row['description']} | "
f"${row['amount']:.2f} | Category: {row['final_category']}"
)
print()
else:
print("No anomalies detected.\n")
if insights["recommendations"]:
print("High-impact categories and suggested budgeting plans:")
for rec in insights["recommendations"]:
print(f"\nCategory '{rec['category']}' accounts for {rec['share'] * 100:.1f}% of spending.")
print("\nSuggested plan:\n")
for step in rec["plan_steps"]:
for line in wrapper.wrap(f"- {step}"):
print(" " + line)
print()
else:
print("No categories exceed the planning threshold.\n")
print("=========================================================================\n")
def run_orchestration(self):
explanations = []
anomaly_flags = []
final_categories = []
csv_path = sys.argv[1] if len(sys.argv) > 1 else None
records_to_show = input(f"Enter the number of records to show (default is 20): ").strip()
records_to_show = int(records_to_show) if records_to_show else 20
print("Loading transactions...")
df = self.__load_transactions(csv_path)
print("Building text features (TF-IDF)...")
vectorizer, x_text = self.__build_text_features(df)
print("Running KMeans clustering...")
kmeans, cluster_labels = self.__perform_clustering(x_text, n_clusters=4)
df["cluster"] = cluster_labels
print("Training Logistic Regression classifier...")
clf, label_encoder = self.__train_classifier(df, x_text)
print("Predicting categories...")
model_categories = self.__predict_categories(df, vectorizer, clf, label_encoder)
df["model_category"] = model_categories
print("Applying rule-based expert system...")
rule_engine = RuleEngine()
for _, row in df.iterrows():
model_cat = row["model_category"]
rule_result = rule_engine.apply_rules(row, model_cat)
final_cat = self.__heuristic_select_category(rule_result["rule_category"], model_cat)
final_categories.append(final_cat)
anomaly_flags.append(rule_result["is_anomaly"])
explanations.append(rule_result["explanation"])
df["final_category"] = final_categories
df["is_anomaly"] = anomaly_flags
df["explanation"] = explanations
print("Generating insights...")
insights = self.__generate_insights(df)
self.__print_report(df, insights, records_to_show)
class TestCaseRunner:
@staticmethod
def run_test():
budget_categorizer = BudgetCategorizer()
budget_categorizer.run_orchestration()
def clear_screen():
command = 'cls' if os.name == 'nt' else 'clear'
os.system(command)
def main():
try:
dependencies = ['numpy', 'pandas', 'scikit-learn']
for d in dependencies: DependencyChecker.ensure_package(d)
clear_screen()
print('*** Budget Categorizer & Spending Insights AI Application ***\n')
TestCaseRunner.run_test()
except Exception as e:
print(e)
if __name__ == '__main__': main()Program’s Output
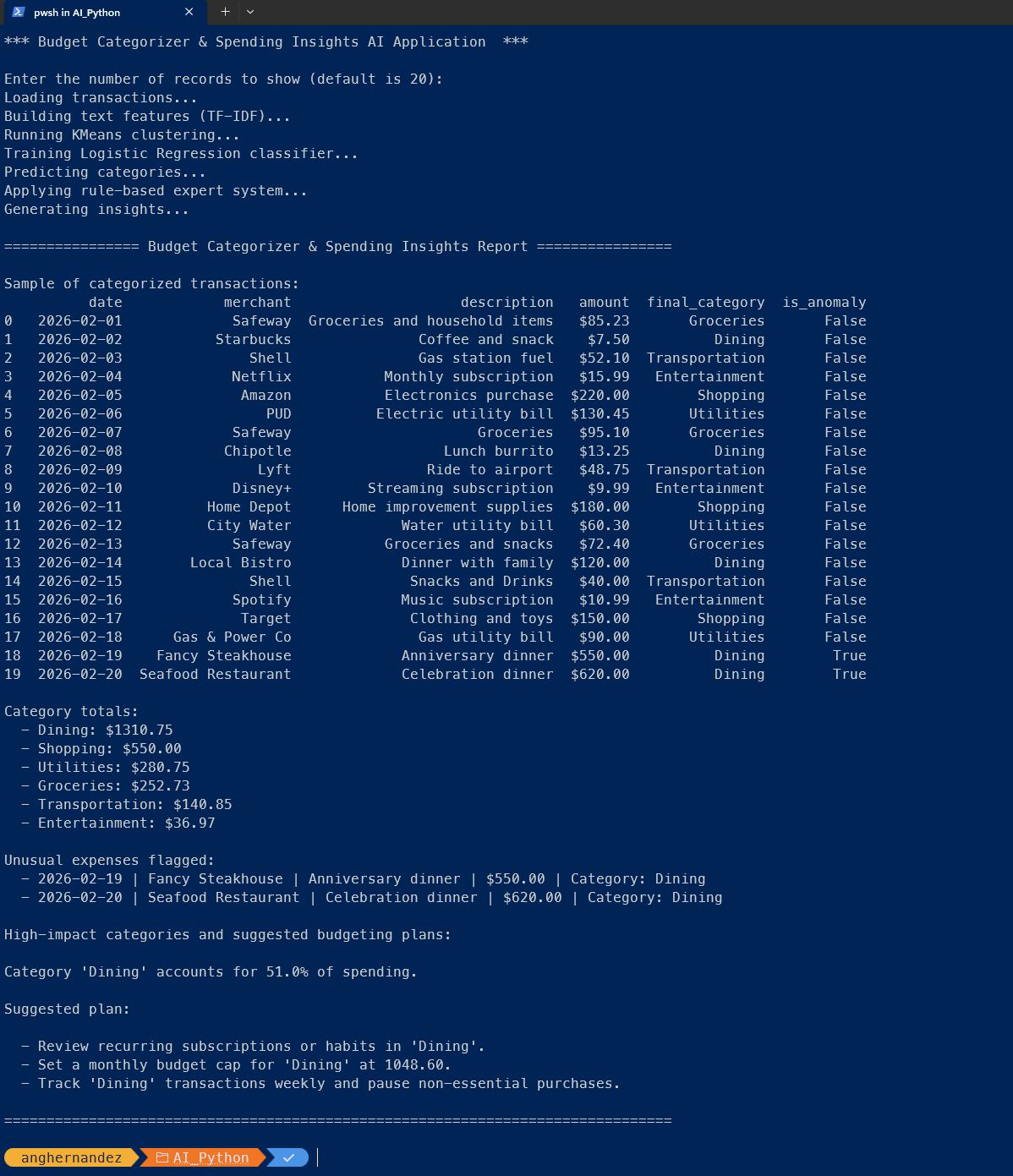
Conclusion
Not every problem needs deep learning. Many problems need clarity. Hybrid AI systems—where rules, models, and structured workflows coexist—remain highly relevant. They offer a pragmatic path to building AI that people can understand, trust, and actually use. That’s not just good AI engineering. It’s good system design.
References
- GeeksforGeeks. (2025, July 23). Natural language processing (NLP) pipeline. Retrieved from
https://www.geeksforgeeks.org/nlp/natural-language-processing-nlp-pipeline - Houstis, E. N., & Rice, J. R. (1992). Artificial intelligence, expert systems & symbolic computing.
North Holland. Retrieved from https://perlego.com/book/1885131/artificial-intelligence-expert-
systems-symbolic-computing-pdf - Saxena, P. (2024). Ultimate machine learning with Scikit-Learn: Unleash the power of Scikit-Learn and
Python to build cutting-edge predictive modeling applications and unlock deeper insights into
machine learning. Orange Education Pvt. Ltd. Retrieved from
https://perlego.com/book/4424696/ultimate-machine-learning-with-scikitlearn-unleash-the-
power-of-scikitlearn-and-python-to-build-cuttingedge-predictive-modeling-applications-and-
unlock-deeper-insights-into-machine-learning-english-edition-pdf - Sharda, R., Delen, D., & Turban, E. (2023). Business intelligence, analytics, data science, and AI (5th
ed.). Pearson.